简单正则+GROK函数入门
2023/05/08 11:19 投稿
hihihi,超简单,超容易理解的!
举例子:
原日志
Apr 17 03:42:12 centreon-upgrade-test systemd[11031]: pam_unix(systemd-user:session): session closed for user apache
Apr 17 03:43:01 centreon-upgrade-test systemd[11086]: pam_unix(systemd-user:session): session opened for user apache by (uid=0)
正则表达式以 ^ 作为开头, $作为结尾。 传统使用的有 [a-z] 表示匹配abcd…..xyz的26个字母字符集内 | \s 表示空格 | \w 表示匹配所有字母数字包括下划线,等同于 [a-zA-Z0-9_] | \d 表示数字
然后用上述所学 我们可以写一个最简单的:
^(?<Month>[a-zA-Z]{1,3})\s+(?<DAY>[0-9]{1,2})\s+(?<Time>[0-9]{1,2}+\:+[0-9]{1,2}+\:+[0-9]{1,2})\s+(?<Hostname>[a-zA-Z0-9|_|-]+)\s+(?<services>[a-zA-Z]+)+\[(?<code>[0-9]+)]:+\s(?<module>[a-zA-Z|_]+)+\((?<progress>[a-zA-Z|:|-]+)\):\s+(?<log>[a-zA-z0-9|\s|(|)|=]+)$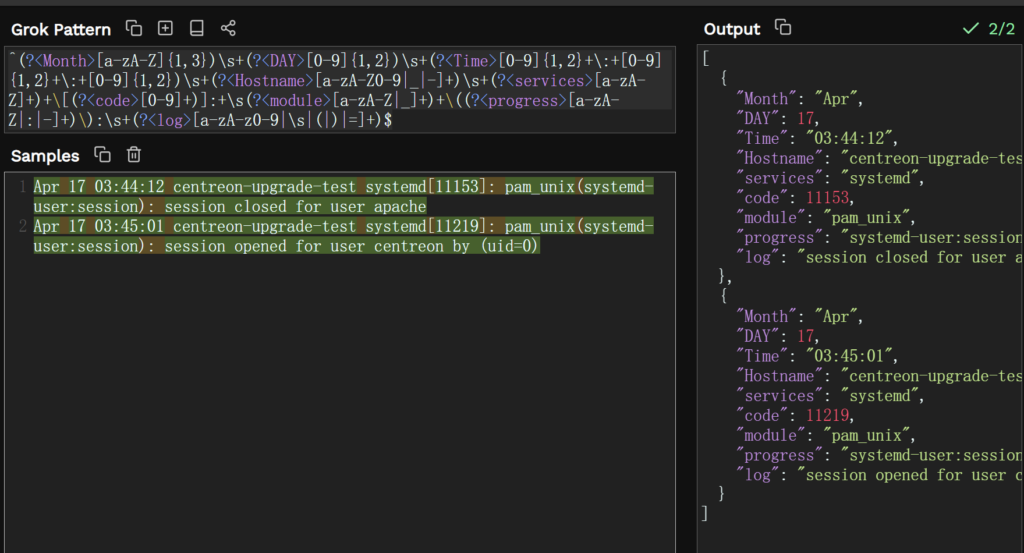
然后根据我们可以再优化一下,变成这样:
^(?<Month>[\w]{1,3})\s+(?<DAY>[\d]{1,2})\s+(?<Time>[\d]{1,2}+\:+[\d]{1,2}+\:+[\d]{1,2})\s+(?<Hostname>[\w|_|-]+)\s+(?<services>[\w]+)+\[(?<code>[\d]+)]:+\s(?<module>[\w]+)+\((?<progress>[\w|:|-]+)\):\s+(?<log>[\w|\s|(|)|=]+)$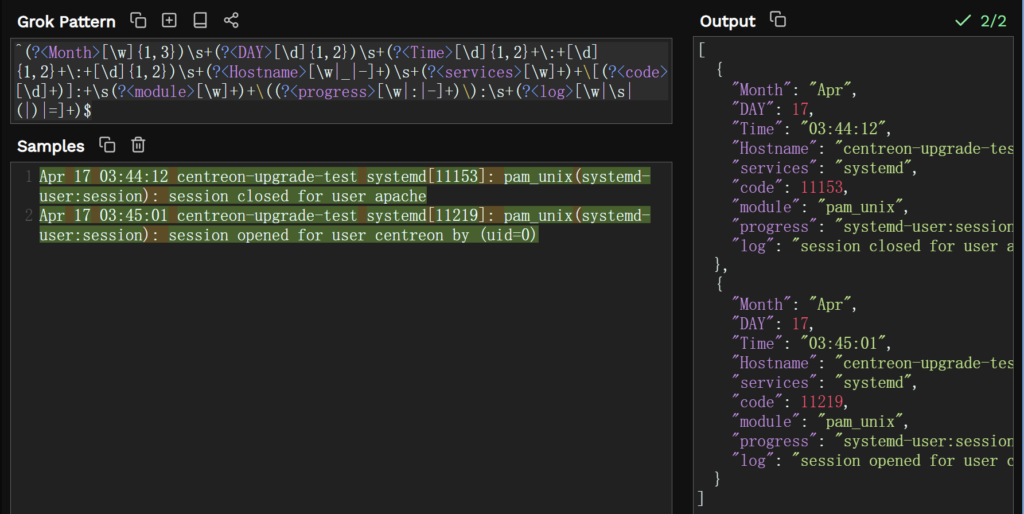
然后呢,现在有了GROK函数根据正则表达式提取特定的值,会更简单。
#函数格式
grok(pattern, escape=False, extend=None)
#GROK语法
%{SYNTAX}
%{SYNTAX:NAME}
#其中SYNTAX表示预定义正则模式,NAME表示分组。
"%{IP}" #等价于r"(?:\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3})"
"%{IP:source_id}" #等价于r"(?P\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3})"
("%{IP}") #等价于r"(\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3})"可以参考这个链接:
https://github.com/garethr/logstash-patterns/blob/master/patterns/logstash
https://help.aliyun.com/document_detail/125480.html
混上grok函数可以这样:
^%{MONTH:month}\s+%{MONTHDAY:day}\s+%{TIME:time}\s+%{HOSTNAME:hostname}\s+%{WORD:services}+\[%{NUMBER:code}\]:\s+(?<module>[a-zA-Z|_]+)+\((?<progress>[a-zA-Z|:|-]+)\):\s+(?<log>[\w|\s|(|)|=]+)$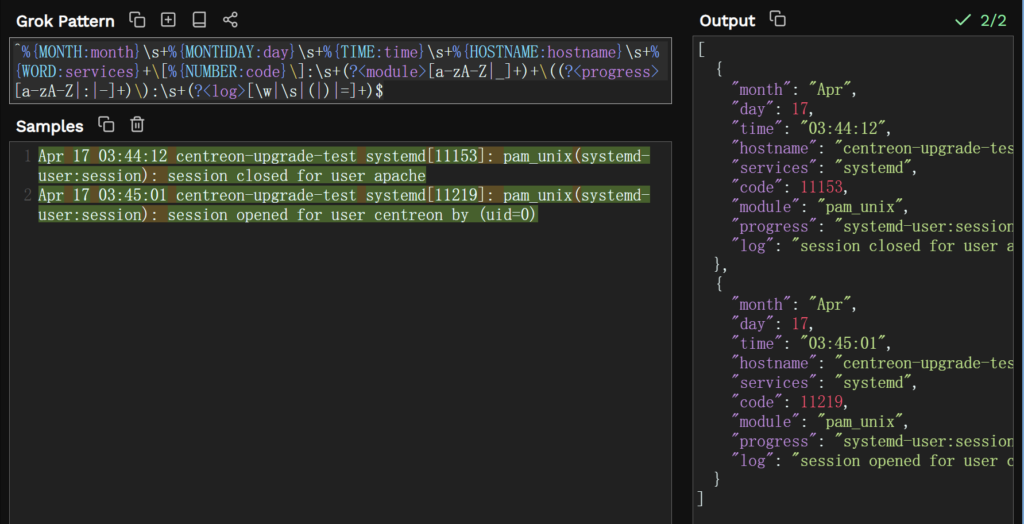
写的可能不是很好,自己可以反复优化,哈哈。
学习一下
赞